rsync Notes:
earlier my rsync dryrun command was:
------------------------------------
/usr/bin/rsync -avvzb --backup-dir=/mnt/rsync-backup/patch-`date +%s`-By-$Username --exclude=$ExcludeFile -n $AbsolutePatchPath/* $RemoteHost:$RemotePath/ | tee /tmp/dry/rsync-push-dryrun-`date +%s`
earlier my rsync command was:
-----------------------------
/usr/bin/rsync -avvzb --backup-dir=/mnt/rsync-backup/patch-`date +%s`-By-$Username --exclude=$ExcludeFile $AbsolutePatchPath/* $RemoteHost:$RemotePath/ | tee /tmp/rsync-push/rsync-push-`date +%s`
following is the details information about the aboe options:
------------------------------------------------------------
-v, --verbose increase verbosity
What is -a option in rsync. [ You might don't need everything... at that time you can use the only needed options. ]
-a, --archive archive mode; equals -rlptgoD (no -H,-A,-X)
-rlptgoD
-r, --recursive recurse into directories
-l, --links copy symlinks as symlinks
-p, --perms preserve permissions [ NO - Need ]
-t, --times preserve modification times [ NO - Need ]
-g, --group preserve group [ No- Need ]
-o, --owner preserve owner (super-user only)
-D same as --devices --specials [ No - Need ]
-z, --compress compress file data during the transfer [ If the rsync is doing in the same computer then no need... it will take more cpu ]
-b, --backup make backups (see --suffix & --backup-dir)
[b --backup-dir=/mnt/rsync-backup/patch-`date +%s`-By-$Username]
--backup-dir=DIR make backups into hierarchy based in DIR
--suffix=SUFFIX backup suffix (default ~ w/o --backup-dir)
-n, --dry-run perform a trial run with no changes made
--existing skip creating new files on receiver [ IMP - will not create the file if its not there ]
--exclude=PATTERN exclude files matching PATTERN
--log-file=FILE log what we're doing to the specified FILE
so the new options can be:
==========================
-vvrlb -backup-dir=<backup_path> [ if doing the dryrun then use -n ]
===========================
Few mrore option that you can consider:
--------------------------------------
-u, --update skip files that are newer on the receiver
-W, --whole-file copy files whole (w/o delta-xfer algorithm)
-e, --rsh=COMMAND specify the remote shell to use
--existing skip creating new files on receiver [ IMP - will not create the file if its not there ]
--ignore-existing skip updating files that exist on receiver
-C, --cvs-exclude auto-ignore files in the same way CVS does
--exclude=PATTERN exclude files matching PATTERN
--exclude-from=FILE read exclude patterns from FILE
--include=PATTERN don't exclude files matching PATTERN
--include-from=FILE read include patterns from FILE
--files-from=FILE read list of source-file names from FILE
-h, --human-readable output numbers in a human-readable format
--progress show progress during transfer
-i, --itemize-changes output a change-summary for all updates
--log-file=FILE log what we're doing to the specified FILE
=== rsync with the ssh command inputs ===
Doing a rsync with the remote host where password bashed login id not enable and where you need to login with the key only.
rsync -avvz -e "ssh -p<port> -i <public-key> -l <user>" <source/> Remote-host:/Remote-path
The above command is passing the "ssh" option after "-e"
If needed you need to provide the port and the key and the username by which you need to do the rsync.
Wednesday, 30 October 2013
Monday, 28 October 2013
rsync and rdiff-backup
Some notes on rsync and rdiff-backup
Some rsync options:
-v, --verbose
-a, --archive [ same as -rlptgoD (no -H, -A, -X)]
-b, --backup make backups (see --suffix & --backup-dir)
--backup-dir=DIR make backups into hierarchy based in DIR
--suffix=SUFFIX backup suffix (default ~ w/o --backup-dir)
-u, --update skip files that are newer on the receiver
-l, --links copy symlinks as symlinks
-p, --perms preserve permissions
-E, --executability preserve executability
-t, --times preserve modification times
-n, --dry-run perform a trial run with no changes made
-e, --rsh=COMMAND specify the remote shell to use
-y, --fuzzy find similar file for basis if no dest file
--compare-dest=DIR also compare received files relative to DIR
--copy-dest=DIR ... and include copies of unchanged files
--link-dest=DIR hardlink to files in DIR when unchanged
-z, --compress compress file data during the transfer
--compress-level=NUM explicitly set compression level
--skip-compress=LIST skip compressing files with suffix in LIST
--exclude-from=FILE read exclude patterns from FILE
-f, --filter=RULE add a file-filtering RULE
-F same as --filter='dir-merge /.rsync-filter'
repeated: --filter='- .rsync-filter'
--exclude=PATTERN exclude files matching PATTERN
--exclude-from=FILE read exclude patterns from FILE
--include=PATTERN don't exclude files matching PATTERN
--include-from=FILE read include patterns from FILE
--files-from=FILE read list of source-file names from FILE
--progress show progress during transfer
--------------- command example START------------------
External links:
http://www.howtoforge.com/backing-up-with-rsync-and-managing-previous-versions-history
http://rdiff-backup.nongnu.org/
https://coderwall.com/p/moabdw
Some rsync options:
-v, --verbose
-a, --archive [ same as -rlptgoD (no -H, -A, -X)]
-b, --backup make backups (see --suffix & --backup-dir)
--backup-dir=DIR make backups into hierarchy based in DIR
--suffix=SUFFIX backup suffix (default ~ w/o --backup-dir)
-u, --update skip files that are newer on the receiver
-l, --links copy symlinks as symlinks
-p, --perms preserve permissions
-E, --executability preserve executability
-t, --times preserve modification times
-n, --dry-run perform a trial run with no changes made
-e, --rsh=COMMAND specify the remote shell to use
-y, --fuzzy find similar file for basis if no dest file
--compare-dest=DIR also compare received files relative to DIR
--copy-dest=DIR ... and include copies of unchanged files
--link-dest=DIR hardlink to files in DIR when unchanged
-z, --compress compress file data during the transfer
--compress-level=NUM explicitly set compression level
--skip-compress=LIST skip compressing files with suffix in LIST
--exclude-from=FILE read exclude patterns from FILE
-f, --filter=RULE add a file-filtering RULE
-F same as --filter='dir-merge /.rsync-filter'
repeated: --filter='- .rsync-filter'
--exclude=PATTERN exclude files matching PATTERN
--exclude-from=FILE read exclude patterns from FILE
--include=PATTERN don't exclude files matching PATTERN
--include-from=FILE read include patterns from FILE
--files-from=FILE read list of source-file names from FILE
--exclude-from=rsync_exclude.txt--progress show progress during transfer
e.g:
rsync -avz source remotehost:destination
rsync -avvz source remotehost:destination [ more verbose ]
rsync -avzb source destination [ It will backup the file that is there as default suffix of ~ and only one earlier version only ]
rsync -avzb --backup-dir=/mnt/rsync-backup/ source destination [ This will create a backup directory at as given [ must have write access ] and copy the file under that as a directory structure. [ Start from the soruce dir name. ]
rsync -avzb --backup-dir=/mnt/rsync-backup/ --suffix=-`date +%s` source remote@destination.
As per the above given example, the command will create a backup of the updating file under "/mnt/rsync-backup/", as per the source of the directory structure and with the file suffix of Filename-epoch time.
So, that you can recover the same file when needed.
--------------- command example START------------------
amit@Amit:~/patch-abc$ rsync -avvzb --backup-dir=/mnt/rsync-backup/patch-`date +%s` --suffix=-`date +%s` * remoteHost:/var/www/
backup_dir is /mnt/rsync-backup/patch-1383060956/
opening connection using: ssh remoteHost rsync --server -vvblogDtprze.iLsf --backup-dir /mnt/rsync-backup/patch-1383060956 --suffix=-1383060956 . /var/www/
backup_dir is /mnt/rsync-backup/patch-1383060956/
sending incremental file list
delta-transmission enabled
advertiser/
advertiser/a.html
ads/ads-file.php is uptodate
unit/abc.property is uptodate
backed up advertiser/a.html to /mnt/rsync-backup/patch-1383060956/advertiser/a.html-1383060956
total: matches=0 hash_hits=0 false_alarms=0 data=78
sent 282 bytes received 55 bytes 51.85 bytes/sec
total size is 104 speedup is 0.31
amit@Amit:~/patch-abc$
NOTE: backup structure will be like following:
amitmund@master:/mnt/rsync-backup$ ls -lR patch-1383060956/
patch-1383060956/:
total 4
drwxrwxr-x 2 amitmund amitmund 4096 Oct 29 21:06 advertiser
patch-1383060956/advertiser:
total 4
-rw-rw-r-- 1 amitmund amitmund 73 Oct 29 21:04 a.html-1383060956
backup_dir is /mnt/rsync-backup/patch-1383060956/
opening connection using: ssh remoteHost rsync --server -vvblogDtprze.iLsf --backup-dir /mnt/rsync-backup/patch-1383060956 --suffix=-1383060956 . /var/www/
backup_dir is /mnt/rsync-backup/patch-1383060956/
sending incremental file list
delta-transmission enabled
advertiser/
advertiser/a.html
ads/ads-file.php is uptodate
unit/abc.property is uptodate
backed up advertiser/a.html to /mnt/rsync-backup/patch-1383060956/advertiser/a.html-1383060956
total: matches=0 hash_hits=0 false_alarms=0 data=78
sent 282 bytes received 55 bytes 51.85 bytes/sec
total size is 104 speedup is 0.31
amit@Amit:~/patch-abc$
NOTE: backup structure will be like following:
amitmund@master:/mnt/rsync-backup$ ls -lR patch-1383060956/
patch-1383060956/:
total 4
drwxrwxr-x 2 amitmund amitmund 4096 Oct 29 21:06 advertiser
patch-1383060956/advertiser:
total 4
-rw-rw-r-- 1 amitmund amitmund 73 Oct 29 21:04 a.html-1383060956
--------------- command example END ------------------
In rsync_exclude.txt file, you can put the file and directory information that need to be excluded: e.g:
External links:
http://www.howtoforge.com/backing-up-with-rsync-and-managing-previous-versions-history
http://rdiff-backup.nongnu.org/
https://coderwall.com/p/moabdw
Friday, 18 October 2013
ssh Tips
You can do much more using ssh and its other services, not only logging to remote system.
Following are few of the tips and example that I feel can help to move quick around.
In ubuntu: following are few of the ssh package that I can you might like to have:
ssh ssh-contact-service ssh-krb5
ssh-askpass sshfp sshm
ssh-askpass-fullscreen sshfs sshmenu
ssh-askpass-gnome sshfs-dbg sshpass
ssh-contact sshguard sshuttle
ssh-contact-client ssh-import-id
If you need to know some information about a package before installing then you can try the following command and from there you can check for Homepage to dig more information.
Command: apt-cache show <packageName>
Example:
apt-cache show ssh-askpass
Package: ssh-askpass
Priority: optional
Section: universe/net
Installed-Size: 160
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Philip Hands <phil@hands.com>
Architecture: amd64
Version: 1:1.2.4.1-9
Depends: libc6 (>= 2.4), libice6 (>= 1:1.0.0), libsm6, libx11-6, libxt6
Filename: pool/universe/s/ssh-askpass/ssh-askpass_1.2.4.1-9_amd64.deb
Size: 34872
MD5sum: e827b5abcc25c19ae6fb0f3eefb5b719
SHA1: 6aa0c3512d9d3dfe361df552a3954a53ec79aad2
SHA256: d6d799ed0a9a1d585e780d4ec2d2c52849fc6ae1e73d02ac5f70e5d29e78201e
Description-en: under X, asks user for a passphrase for ssh-add
This is Jim Knoble's free implementation of the ssh-askpass program.
.
Jim calls this x11-ssh-askpass, but I've decided to call it ssh-askpass to
make it easier to find, because this is almost certainly the version you
want. Other ssh-askpass programs are available, some of which may integrate
better into various desktop environments.
Homepage: http://www.jmknoble.net/software/x11-ssh-askpass/
Description-md5: 5b9411f94446cbb46230c152b2591705
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Origin: Ubuntu
Following are few of the tips and example that I feel can help to move quick around.
In ubuntu: following are few of the ssh package that I can you might like to have:
ssh ssh-contact-service ssh-krb5
ssh-askpass sshfp sshm
ssh-askpass-fullscreen sshfs sshmenu
ssh-askpass-gnome sshfs-dbg sshpass
ssh-contact sshguard sshuttle
ssh-contact-client ssh-import-id
If you need to know some information about a package before installing then you can try the following command and from there you can check for Homepage to dig more information.
Command: apt-cache show <packageName>
Example:
apt-cache show ssh-askpass
Package: ssh-askpass
Priority: optional
Section: universe/net
Installed-Size: 160
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Philip Hands <phil@hands.com>
Architecture: amd64
Version: 1:1.2.4.1-9
Depends: libc6 (>= 2.4), libice6 (>= 1:1.0.0), libsm6, libx11-6, libxt6
Filename: pool/universe/s/ssh-askpass/ssh-askpass_1.2.4.1-9_amd64.deb
Size: 34872
MD5sum: e827b5abcc25c19ae6fb0f3eefb5b719
SHA1: 6aa0c3512d9d3dfe361df552a3954a53ec79aad2
SHA256: d6d799ed0a9a1d585e780d4ec2d2c52849fc6ae1e73d02ac5f70e5d29e78201e
Description-en: under X, asks user for a passphrase for ssh-add
This is Jim Knoble's free implementation of the ssh-askpass program.
.
Jim calls this x11-ssh-askpass, but I've decided to call it ssh-askpass to
make it easier to find, because this is almost certainly the version you
want. Other ssh-askpass programs are available, some of which may integrate
better into various desktop environments.
Homepage: http://www.jmknoble.net/software/x11-ssh-askpass/
Description-md5: 5b9411f94446cbb46230c152b2591705
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Origin: Ubuntu
Tuesday, 15 October 2013
How to at AWS
Over here I will be putting some of my notes on how to do things at aws, to the best knowledge to me. I know there other good ways to do the same things.
-> How to create your own instance image.
Most of the time you create a image from the one of the listed image from AWS and work on the same image with your settings. Once you do all your base settings, its always good to create an instance image from that image/setting so that you can use the same for the future usages:
Following are few steps using that you can create an image,.
1. Login to your same instance where you have configured the instance.
2. For some standard, it good to create a directory [ mostly you can think of at /mnt ]. e.g: sudo mkdir /mnt/instanceImage/ [ I am using a ubuntu instance./ ]
3. command:
sudo ec2-bundle-vol -d /mnt/instanceImage -k YourPrivateKeyPath -c YourCertificatePath -u YourAWSAccountNumber
This above command will bundle your instance image.
4. command:
Some Related Commands:
ec2-bundle-vol --help
MANDATORY PARAMETERS
-c, --cert PATH The path to the user's PEM encoded RSA public key certificate file.
-k, --privatekey PATH The path to the user's PEM encoded RSA private key file.
-u, --user USER The user's EC2 user ID (Note: AWS account number, NOT Access Key ID).
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
-d, --destination PATH The directory to create the bundle in. Defaults to '/tmp'.
--ec2cert PATH The path to the EC2 X509 public key certificate bundled into the AMI.
Defaults to '/home/ubuntu/ec2/etc/ec2/amitools/cert-ec2.pem'.
-r, --arch ARCHITECTURE Specify target architecture. One of ["i386", "x86_64"]
--productcodes PRODUCT_CODES Default product codes attached to the image at registration time.
Comma separated list of product codes.
--kernel ID Id of the default kernel to launch the AMI with.
--ramdisk ID Id of the default ramdisk to launch the AMI with.
-B, --block-device-mapping MAPS Default block-device-mapping scheme to launch the AMI with. This scheme
defines how block devices may be exposed to an EC2 instance of this AMI
if the instance-type of the instance is entitled to the specified device.
The scheme is a comma-separated list of key=value pairs, where each key
is a "virtual-name" and each value, the corresponding native device name
desired. Possible virtual-names are:
- "ami": denotes the root file system device, as seen by the instance.
- "root": denotes the root file system device, as seen by the kernel.
- "swap": denotes the swap device, if present.
- "ephemeralN": denotes Nth ephemeral store; N is a non-negative integer.
Note that the contents of the AMI form the root file system. Samples of
block-device-mappings are:
- "ami=sda1,root=/dev/sda1,ephemeral0=sda2,swap=sda3"
- "ami=0,root=/dev/dsk/c0d0s0,ephemeral0=1"
-a, --all Include all directories in the volume being bundled, including those
on remotely mounted filesystems.
-e, --exclude DIR1,DIR2,... A comma-separated list of absolute directory paths to exclude. This
option overrides the "--all" option.
-p, --prefix PREFIX The filename prefix for bundled AMI files. Defaults to "image".
-s, --size MB The size, in MB (1024 * 1024 bytes), of the image file to create.
The maximum size is 10240 MB.
--[no-]inherit Inherit instance metadata. Enabled by default.
Bundling will fail if inherit is enabled but instance data
is not accessible, for example not bundling an EC2 instance.
-v, --volume PATH The absolute path to the mounted volume to be bundled. Defaults to "/".
--fstab PATH The absolute path to the fstab to be bundled into the image.
--generate-fstab Inject a generated EC2 fstab. (Only use this if you are not rebundling
an existing instance.)
----
ec2-bundle-image --help
MANDATORY PARAMETERS
-c, --cert PATH The path to the user's PEM encoded RSA public key certificate file.
-k, --privatekey PATH The path to the user's PEM encoded RSA private key file.
-u, --user USER The user's EC2 user ID (Note: AWS account number, NOT Access Key ID).
-i, --image PATH The path to the file system image to bundle.
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
-d, --destination PATH The directory to create the bundle in. Defaults to '/tmp'.
--ec2cert PATH The path to the EC2 X509 public key certificate bundled into the AMI.
Defaults to '/etc/ec2/amitools/cert-ec2.pem'.
-r, --arch ARCHITECTURE Specify target architecture. One of ["i386", "x86_64"]
--productcodes PRODUCT_CODES Default product codes attached to the image at registration time.
Comma separated list of product codes.
--kernel ID Id of the default kernel to launch the AMI with.
--ramdisk ID Id of the default ramdisk to launch the AMI with.
-B, --block-device-mapping MAPS Default block-device-mapping scheme to launch the AMI with. This scheme
defines how block devices may be exposed to an EC2 instance of this AMI
if the instance-type of the instance is entitled to the specified device.
The scheme is a comma-separated list of key=value pairs, where each key
is a "virtual-name" and each value, the corresponding native device name
desired. Possible virtual-names are:
- "ami": denotes the root file system device, as seen by the instance.
- "root": denotes the root file system device, as seen by the kernel.
- "swap": denotes the swap device, if present.
- "ephemeralN": denotes Nth ephemeral store; N is a non-negative integer.
Note that the contents of the AMI form the root file system. Samples of
block-device-mappings are:
- "ami=sda1,root=/dev/sda1,ephemeral0=sda2,swap=sda3"
- "ami=0,root=/dev/dsk/c0d0s0,ephemeral0=1"
-p, --prefix PREFIX The filename prefix for bundled AMI files. Defaults to image name.
---
ec2-upload-bundle --help
MANDATORY PARAMETERS
-b, --bucket BUCKET The bucket to use. This is an S3 bucket,
followed by an optional S3 key prefix using '/' as a delimiter.
-a, --access-key USER The user's AWS access key ID.
-s, --secret-key PASSWORD The user's AWS secret access key.
-m, --manifest PATH The path to the manifest file.
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
--url URL The S3 service URL. Defaults to https://s3.amazonaws.com.
--acl ACL The access control list policy ["public-read" | "aws-exec-read"].
Defaults to "aws-exec-read".
-d, --directory DIRECTORY The directory containing the bundled AMI parts to upload.
Defaults to the directory containing the manifest.
--part PART Upload the specified part and upload all subsequent parts.
--retry Automatically retry failed uploads.
--skipmanifest Do not upload the manifest.
--location LOCATION The location of the bucket to upload to [EU,US,us-west-1,ap-southeast-1].
-> How to create your own instance image.
Most of the time you create a image from the one of the listed image from AWS and work on the same image with your settings. Once you do all your base settings, its always good to create an instance image from that image/setting so that you can use the same for the future usages:
Following are few steps using that you can create an image,.
1. Login to your same instance where you have configured the instance.
2. For some standard, it good to create a directory [ mostly you can think of at /mnt ]. e.g: sudo mkdir /mnt/instanceImage/ [ I am using a ubuntu instance./ ]
3. command:
sudo ec2-bundle-vol -d /mnt/instanceImage -k YourPrivateKeyPath -c YourCertificatePath -u YourAWSAccountNumber
This above command will bundle your instance image.
4. command:
sudo ec2-upload-bundle -b bucketName -m PathToManifest -a YourAccessKeyUser -s YourSecretKeyPassword
Some Related Commands:
ec2-bundle-vol --help
MANDATORY PARAMETERS
-c, --cert PATH The path to the user's PEM encoded RSA public key certificate file.
-k, --privatekey PATH The path to the user's PEM encoded RSA private key file.
-u, --user USER The user's EC2 user ID (Note: AWS account number, NOT Access Key ID).
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
-d, --destination PATH The directory to create the bundle in. Defaults to '/tmp'.
--ec2cert PATH The path to the EC2 X509 public key certificate bundled into the AMI.
Defaults to '/home/ubuntu/ec2/etc/ec2/amitools/cert-ec2.pem'.
-r, --arch ARCHITECTURE Specify target architecture. One of ["i386", "x86_64"]
--productcodes PRODUCT_CODES Default product codes attached to the image at registration time.
Comma separated list of product codes.
--kernel ID Id of the default kernel to launch the AMI with.
--ramdisk ID Id of the default ramdisk to launch the AMI with.
-B, --block-device-mapping MAPS Default block-device-mapping scheme to launch the AMI with. This scheme
defines how block devices may be exposed to an EC2 instance of this AMI
if the instance-type of the instance is entitled to the specified device.
The scheme is a comma-separated list of key=value pairs, where each key
is a "virtual-name" and each value, the corresponding native device name
desired. Possible virtual-names are:
- "ami": denotes the root file system device, as seen by the instance.
- "root": denotes the root file system device, as seen by the kernel.
- "swap": denotes the swap device, if present.
- "ephemeralN": denotes Nth ephemeral store; N is a non-negative integer.
Note that the contents of the AMI form the root file system. Samples of
block-device-mappings are:
- "ami=sda1,root=/dev/sda1,ephemeral0=sda2,swap=sda3"
- "ami=0,root=/dev/dsk/c0d0s0,ephemeral0=1"
-a, --all Include all directories in the volume being bundled, including those
on remotely mounted filesystems.
-e, --exclude DIR1,DIR2,... A comma-separated list of absolute directory paths to exclude. This
option overrides the "--all" option.
-p, --prefix PREFIX The filename prefix for bundled AMI files. Defaults to "image".
-s, --size MB The size, in MB (1024 * 1024 bytes), of the image file to create.
The maximum size is 10240 MB.
--[no-]inherit Inherit instance metadata. Enabled by default.
Bundling will fail if inherit is enabled but instance data
is not accessible, for example not bundling an EC2 instance.
-v, --volume PATH The absolute path to the mounted volume to be bundled. Defaults to "/".
--fstab PATH The absolute path to the fstab to be bundled into the image.
--generate-fstab Inject a generated EC2 fstab. (Only use this if you are not rebundling
an existing instance.)
----
ec2-bundle-image --help
MANDATORY PARAMETERS
-c, --cert PATH The path to the user's PEM encoded RSA public key certificate file.
-k, --privatekey PATH The path to the user's PEM encoded RSA private key file.
-u, --user USER The user's EC2 user ID (Note: AWS account number, NOT Access Key ID).
-i, --image PATH The path to the file system image to bundle.
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
-d, --destination PATH The directory to create the bundle in. Defaults to '/tmp'.
--ec2cert PATH The path to the EC2 X509 public key certificate bundled into the AMI.
Defaults to '/etc/ec2/amitools/cert-ec2.pem'.
-r, --arch ARCHITECTURE Specify target architecture. One of ["i386", "x86_64"]
--productcodes PRODUCT_CODES Default product codes attached to the image at registration time.
Comma separated list of product codes.
--kernel ID Id of the default kernel to launch the AMI with.
--ramdisk ID Id of the default ramdisk to launch the AMI with.
-B, --block-device-mapping MAPS Default block-device-mapping scheme to launch the AMI with. This scheme
defines how block devices may be exposed to an EC2 instance of this AMI
if the instance-type of the instance is entitled to the specified device.
The scheme is a comma-separated list of key=value pairs, where each key
is a "virtual-name" and each value, the corresponding native device name
desired. Possible virtual-names are:
- "ami": denotes the root file system device, as seen by the instance.
- "root": denotes the root file system device, as seen by the kernel.
- "swap": denotes the swap device, if present.
- "ephemeralN": denotes Nth ephemeral store; N is a non-negative integer.
Note that the contents of the AMI form the root file system. Samples of
block-device-mappings are:
- "ami=sda1,root=/dev/sda1,ephemeral0=sda2,swap=sda3"
- "ami=0,root=/dev/dsk/c0d0s0,ephemeral0=1"
-p, --prefix PREFIX The filename prefix for bundled AMI files. Defaults to image name.
---
ec2-upload-bundle --help
MANDATORY PARAMETERS
-b, --bucket BUCKET The bucket to use. This is an S3 bucket,
followed by an optional S3 key prefix using '/' as a delimiter.
-a, --access-key USER The user's AWS access key ID.
-s, --secret-key PASSWORD The user's AWS secret access key.
-m, --manifest PATH The path to the manifest file.
OPTIONAL PARAMETERS
-h, --help Display this help message and exit.
--version Display the version and copyright notice and then exit.
--manual Display the user manual and exit.
--batch Run in batch mode. No interactive prompts.
--debug Display debug messages.
--url URL The S3 service URL. Defaults to https://s3.amazonaws.com.
--acl ACL The access control list policy ["public-read" | "aws-exec-read"].
Defaults to "aws-exec-read".
-d, --directory DIRECTORY The directory containing the bundled AMI parts to upload.
Defaults to the directory containing the manifest.
--part PART Upload the specified part and upload all subsequent parts.
--retry Automatically retry failed uploads.
--skipmanifest Do not upload the manifest.
--location LOCATION The location of the bucket to upload to [EU,US,us-west-1,ap-southeast-1].
Friday, 11 October 2013
Readme Links
Readme links:
19. PostgreSQL
http://www.tutorialspoint.com/postgresql/index.htm
18. Online free tutorial site
http://www.tutorialspoint.com/
17. Swift openStack architecture
http://swiftstack.com/openstack-swift/architecture/
16. Open stack technology
https://wiki.openstack.org/wiki/Main_Page
15. Object Store with Swift from open stack.
https://wiki.openstack.org/wiki/Swift
14. HDFS file system
http://www.aosabook.org/en/hdfs.html
13. VolunteerComputing - Boinc
http://boinc.berkeley.edu/trac/wiki/VolunteerComputing
12. Highscalability posts
http://highscalability.com/all-posts/
11. How twitter stores
http://highscalability.com/blog/2011/12/19/how-twitter-stores-250-million-tweets-a-day-using-mysql.html
10 .Pomegranate-storing-billions-of-tiny-files
http://highscalability.com/blog/2010/8/30/pomegranate-storing-billions-and-billions-of-tiny-little-fil.html
9. Apache ambari, for hadoop env monitoring and deployment.
http://ambari.apache.org/
8. capistrano deployment:
http://www.youtube.com/watch?v=ulK-lhv8eI0
7. Installing Graphite from Source:
http://www.youtube.com/watch?v=0-g--_Be2jc
6. Apache foundation announce:
https://blogs.apache.org/foundation/entry/the_apache_software_foundation_announces48
5. About NoSQL:
http://wikibon.org/wiki/v/21_NoSQL_Innovators_to_Look_for_in_2020
4. Heroku:
http://www.youtube.com/watch?v=VZgHItD9bAQ [ Heroku ]
http://chimera.labs.oreilly.com/books/1234000000018/index.html [ Heroku book ]
3. Haskell:
https://www.fpcomplete.com/
http://www.youtube.com/watch?v=Fqi0Xu2Enaw#!
2. OPA
http://www.youtube.com/watch?v=yGpj7HwAK44#!
1. Mongodb:
http://www.phloxblog.in/handling-requests-google-dart-node-js-mongodb/?goback=.gde_2340731_member_276496159#!
19. PostgreSQL
http://www.tutorialspoint.com/postgresql/index.htm
18. Online free tutorial site
http://www.tutorialspoint.com/
17. Swift openStack architecture
http://swiftstack.com/openstack-swift/architecture/
16. Open stack technology
https://wiki.openstack.org/wiki/Main_Page
15. Object Store with Swift from open stack.
https://wiki.openstack.org/wiki/Swift
14. HDFS file system
http://www.aosabook.org/en/hdfs.html
13. VolunteerComputing - Boinc
http://boinc.berkeley.edu/trac/wiki/VolunteerComputing
12. Highscalability posts
http://highscalability.com/all-posts/
11. How twitter stores
http://highscalability.com/blog/2011/12/19/how-twitter-stores-250-million-tweets-a-day-using-mysql.html
10 .Pomegranate-storing-billions-of-tiny-files
http://highscalability.com/blog/2010/8/30/pomegranate-storing-billions-and-billions-of-tiny-little-fil.html
9. Apache ambari, for hadoop env monitoring and deployment.
http://ambari.apache.org/
8. capistrano deployment:
http://www.youtube.com/watch?v=ulK-lhv8eI0
7. Installing Graphite from Source:
http://www.youtube.com/watch?v=0-g--_Be2jc
6. Apache foundation announce:
https://blogs.apache.org/foundation/entry/the_apache_software_foundation_announces48
5. About NoSQL:
http://wikibon.org/wiki/v/21_NoSQL_Innovators_to_Look_for_in_2020
4. Heroku:
http://www.youtube.com/watch?v=VZgHItD9bAQ [ Heroku ]
http://chimera.labs.oreilly.com/books/1234000000018/index.html [ Heroku book ]
3. Haskell:
https://www.fpcomplete.com/
http://www.youtube.com/watch?v=Fqi0Xu2Enaw#!
2. OPA
http://www.youtube.com/watch?v=yGpj7HwAK44#!
1. Mongodb:
http://www.phloxblog.in/handling-requests-google-dart-node-js-mongodb/?goback=.gde_2340731_member_276496159#!
Thursday, 10 October 2013
quick work around linux Unix.
This note is a collection of few quick work around to do some linux unix work.
*) diff:
diff -w file1 file2 [ This will remove empty space. ]
diffing b/w local and remote files
diff -w localfile <(ssh remote_server 'cat remote_file')
NOTE: there should not have any space between <(
NOTE: It will be nice if you have a ssh config settings.
diffing b/w two remote files
diff -w <(ssh remote1 'cat remote1_file') <(ssh remote2 'cat remote2_file')
*) diff:
diff -w file1 file2 [ This will remove empty space. ]
diffing b/w local and remote files
diff -w localfile <(ssh remote_server 'cat remote_file')
NOTE: there should not have any space between <(
NOTE: It will be nice if you have a ssh config settings.
diffing b/w two remote files
diff -w <(ssh remote1 'cat remote1_file') <(ssh remote2 'cat remote2_file')
Wednesday, 9 October 2013
basic_perl_script_to_connect_mysql
This is a simple perl program to connect to mysql database and show the tables, and later how to run the same code in apache web server.
perl code:
#!/usr/bin/perl -w
use DBI;
print "Content-type: text/html\n\n";
## mysql user database name
$db ="mysql";
## mysql database user name
$user = "root";
## mysql database password
$pass = "yourPassword";
## user hostname : This should be "localhost" but it can be diffrent too
$host="localhost";
## SQL query
$query = "show tables";
$dbh = DBI->connect("DBI:mysql:$db:$host", $user, $pass);
$sqlQuery = $dbh->prepare($query)
or die "Can't prepare $query: $dbh->errstr\n";
$sqlQuery->execute
#$rv = $sqlQuery->execute
or die "can't execute the query: $sqlQuery->errstr";
print "<h3>********** My Perl DBI Test ***************</h3>";
print "<p>Here is a list of tables in the MySQL database $db.</p>";
while (@row= $sqlQuery->fetchrow_array()) {
my $tables = $row[0];
print "$tables\n<br>";
}
#$rc = $sqlQuery->finish;
$sqlQuery->finish;
exit(0);
To run the same in the web:
# Lets say you have apache web server:
copy the same code at /usr/lib/cgi-bin directory with execution permission and then you can use [ http://localhost/cgi-bin/perlScript.pl ] at your web browser.
Make sure that your apache we server is running and the perl script is there at /usr/lib/cgi-bin directory with execution permission.
http://httpd.apache.org/docs/2.0/howto/cgi.html
For Python to connect to DB and other DB related example:
http://zetcode.com/db/mysqlpython/
Simple code to execute the code at web:
cat pythonHelloWorld.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# enable debugging
import cgitb
cgitb.enable()
print "Content-Type: text/plain;charset=utf-8"
print
print "Hello World!"
NOTE: Make sure, the script in executable permission and under the cgi-bin directory.
Script compare:
http://hyperpolyglot.org/scripting
perl code:
#!/usr/bin/perl -w
use DBI;
print "Content-type: text/html\n\n";
## mysql user database name
$db ="mysql";
## mysql database user name
$user = "root";
## mysql database password
$pass = "yourPassword";
## user hostname : This should be "localhost" but it can be diffrent too
$host="localhost";
## SQL query
$query = "show tables";
$dbh = DBI->connect("DBI:mysql:$db:$host", $user, $pass);
$sqlQuery = $dbh->prepare($query)
or die "Can't prepare $query: $dbh->errstr\n";
$sqlQuery->execute
#$rv = $sqlQuery->execute
or die "can't execute the query: $sqlQuery->errstr";
print "<h3>********** My Perl DBI Test ***************</h3>";
print "<p>Here is a list of tables in the MySQL database $db.</p>";
while (@row= $sqlQuery->fetchrow_array()) {
my $tables = $row[0];
print "$tables\n<br>";
}
#$rc = $sqlQuery->finish;
$sqlQuery->finish;
exit(0);
To run the same in the web:
# Lets say you have apache web server:
copy the same code at /usr/lib/cgi-bin directory with execution permission and then you can use [ http://localhost/cgi-bin/perlScript.pl ] at your web browser.
Make sure that your apache we server is running and the perl script is there at /usr/lib/cgi-bin directory with execution permission.
http://httpd.apache.org/docs/2.0/howto/cgi.html
For Python to connect to DB and other DB related example:
http://zetcode.com/db/mysqlpython/
Simple code to execute the code at web:
cat pythonHelloWorld.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# enable debugging
import cgitb
cgitb.enable()
print "Content-Type: text/plain;charset=utf-8"
print "Hello World!"
NOTE: Make sure, the script in executable permission and under the cgi-bin directory.
Script compare:
http://hyperpolyglot.org/scripting
Tuesday, 8 October 2013
Quick scp and ssh using ssh_config file
Its good to use a key and different port number to access of our server. So to make our life easy we use the ".ssh/config" file to set the setting.
Using the .ssh/config we can connect to remote server, without using the ssh key option like -p <port#> -i <key>.
A sample of the ssh config file is:
Host hostname_of_your_wish
HostName OriginalHostDNS/IP_address
Port ThePortNumbre_Where_ssh_runs
User UsernameToLogin
IdentityFile PathToTheKeyFile
Example:
Host weserver1
HostName webserver1.example.com
Port 9876
User amitmund
IdentityFile LiveExample.pem
Once you set this kind of config file, next time you just time to "ssh webserver1" and you are in the webserver1.example.com host.
How to use the scp using the same config file.
The option is -F <filename>
so, you can do:
scp -F ~/.ssh/config testFile webserver1:~
The above command will copy your testFile to the webserver1.example.com site.
I have added an alias of scp command to my profile file that, even I don't have to type the -F options. Following setting I have added in my alias:
# -r Recursively copy entire directories. Note that scp follows symbolic links encountered in the tree traversal. [ Follow Symlink ]
# -F ssh_config
alias='/usr/bin/scp -r -F ~/.ssh/config'
And that help me a lot.
Using the .ssh/config we can connect to remote server, without using the ssh key option like -p <port#> -i <key>.
A sample of the ssh config file is:
Host hostname_of_your_wish
HostName OriginalHostDNS/IP_address
Port ThePortNumbre_Where_ssh_runs
User UsernameToLogin
IdentityFile PathToTheKeyFile
Example:
Host weserver1
HostName webserver1.example.com
Port 9876
User amitmund
IdentityFile LiveExample.pem
Once you set this kind of config file, next time you just time to "ssh webserver1" and you are in the webserver1.example.com host.
How to use the scp using the same config file.
The option is -F <filename>
so, you can do:
scp -F ~/.ssh/config testFile webserver1:~
The above command will copy your testFile to the webserver1.example.com site.
I have added an alias of scp command to my profile file that, even I don't have to type the -F options. Following setting I have added in my alias:
# -r Recursively copy entire directories. Note that scp follows symbolic links encountered in the tree traversal. [ Follow Symlink ]
# -F ssh_config
alias='/usr/bin/scp -r -F ~/.ssh/config'
And that help me a lot.
Friday, 4 October 2013
Neo4j and cypher query language
Neo4j and cypher query language:
Read me links:
http://amitmund.blogspot.in/2013/10/installing-neo4j-at-ubuntu-unix.html
http://amitmund.blogspot.in/2013/10/nosql-and-graph-databases.html


























Few More links:
http://docs.neo4j.org/chunked/1.9.4/
http://www.neo4j.org/learn/cypher
http://docs.neo4j.org/chunked/1.9.4/
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
Read me links:
http://amitmund.blogspot.in/2013/10/installing-neo4j-at-ubuntu-unix.html
http://amitmund.blogspot.in/2013/10/nosql-and-graph-databases.html

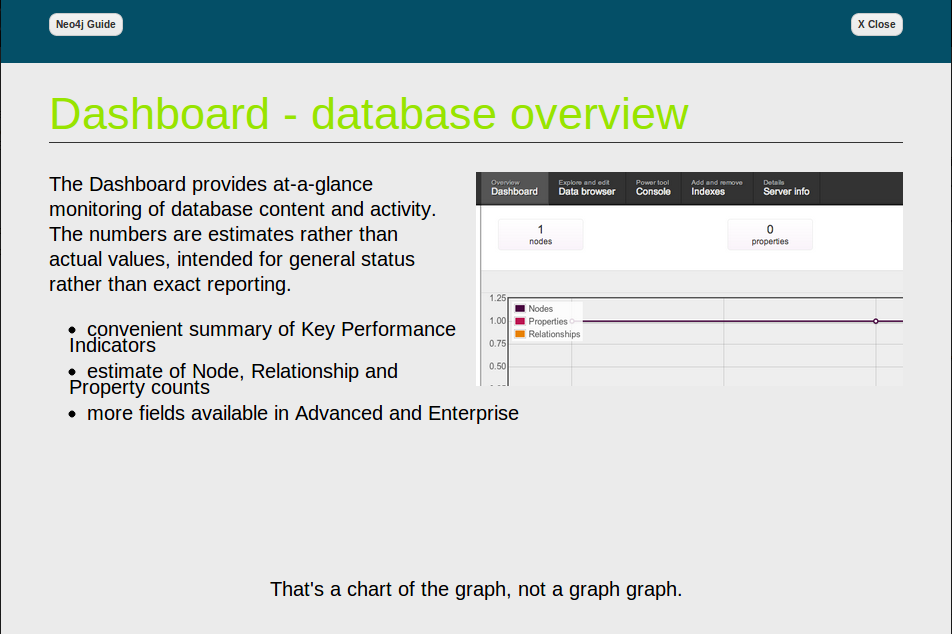
























Few More links:
http://docs.neo4j.org/chunked/1.9.4/
http://www.neo4j.org/learn/cypher
http://docs.neo4j.org/chunked/1.9.4/
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
Installing Neo4j at ubuntu-unix
How to Install Neo4j at Linux:
1. Download the package from : http://www.neo4j.org/download [ I am using Community version ]
http://www.neo4j.org/download_thanks?edition=community&release=1.9.4&platform=unix
2. Extract the downloaded file. [ tar -zxvf neo4j-community-1.9.4-unix.tar.gz ]
3. bin/neo4j start [ from terminal to start ]
4. Open http://localhost:7474 from the web UI [ http://localhost:7474/webadmin/ ]
NOTE: you need to have java for Neo4j
For ubuntu: [ sudo apt-get install openjdk-7-jre-headless ]
set JAVA_HOME [ As per Neo4J ], It is prefer Oracle's Java. [ But Openjdk also works ]
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/
---- Got the following msg at my system but its working fine :) ---
# bin/neo4j start
WARNING: Max 1024 open files allowed, minimum of 40 000 recommended. See the Neo4j manual.
WARNING! You are using an unsupported Java runtime. Please use Oracle(R) Java(TM) Runtime Environment 7.
Using additional JVM arguments: -server -XX:+DisableExplicitGC -Dorg.neo4j.server.properties=conf/neo4j-server.properties -Djava.util.logging.config.file=conf/logging.properties -Dlog4j.configuration=file:conf/log4j.properties -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled
Starting Neo4j Server...WARNING: not changing user
process [12690]... waiting for server to be ready....... OK.
Go to http://localhost:7474/webadmin/ for administration interfac
------------------- END ------------------
Installing sublime text fupport for Cypher and Neo4j:
http://vimeo.com/64886333
https://github.com/sqlcook/Sublime-Neo4j
Further study:
http://amitmund.blogspot.in/2013/10/nosql-and-graph-databases.html
External Links:
http://www.dataversity.net/featured-video-evolving-neo4j-for-the-cloud/
NoSQL and Graph Databases
Few collection on Graph Databases:
http://en.wikipedia.org/wiki/Relational_database
A relational database is a database that has a collection of tables of data items, all of which is formally described and organized according to the relational model. The term is in contrast to only one table as the database, and in contrast to other models which also have many tables in one database.
In the relational model, each table schema must identify a column or group of columns, called the primary key, to uniquely identify each row. A relationship can then be established between each row in the table and a row in another table by creating a foreign key, a column or group of columns in one table that points to the primary key of another table. The relational model offers various levels of refinement of table organization and reorganization called database normalization. (See Normalization below.) The database management system (DBMS) of a relational database is called an RDBMS, and is the software of a relational database.
NoSQL: Not only SQL
http://en.wikipedia.org/wiki/NoSQL
http://nosql-database.org/
The name attempted to label the emergence of a growing number of non-relational, distributed data stores that often did not attempt to provide atomicity, consistency, isolation and durability guarantees that are key attributes of classic relational database systems.
A NoSQL database provides a mechanism for storage and retrieval of data that employs less constrained consistency models than traditional relational databases. Motivations for this approach include simplicity of design, horizontal scaling and finer control over availability. NoSQL databases are often highly optimized key–value stores intended for simple retrieval and appending operations, with the goal being significant performance benefits in terms of latency and throughput. NoSQL databases are finding significant and growing industry use in big data and real-time web applications. NoSQL systems are also referred to as "Not only SQL" to emphasize that they do in fact allow SQL-like query languages to be used.
There have been various approaches to classify NoSQL databases, each with different categories and subcategories. Because of the variety of approaches and overlaps it is difficult to get and maintain an overview of non-relational databases. Nevertheless, the basic classification that most would agree on is based on data model. A few of these and their prototypes are:
Document Store:
Different implementations offer different ways of organizing and/or grouping documents:
Documents are addressed in the database via a unique key that represents that document. One of the other defining characteristics of a document-oriented database is that, beyond the simple key-document (or key–value) lookup that you can use to retrieve a document, the database will offer an API or query language that will allow retrieval of documents based on their contents. Some NoSQL document stores offer an alternative way to retrieve information using MapReduce techniques, in CouchDB the usage of MapReduce is mandatory if you want to retrieve documents based on the contents, this is called "Views" and it's an indexed collection with the results of the MapReduce algorithms.
NAME Language Notes
Apache CouchDB Erlang JSON database
MongoDB c++, C#, Go BSON store (binary format json)
SimpleDB Erlang Online Service
Graph:
This kind of database is designed for data whose relations are well represented as a graph (elements interconnected with an undetermined number of relations between them). The kind of data could be social relations, public transport links, road maps or network topologies, for example.
FlockDB Scala
InfiniteGraph Java
Neo4j Java
AllegroGraph SPAROL RDF GraphStore
Key-Value Stores:
Key–value stores allow the application to store its data in a schema-less way. The data could be stored in a datatype of a programming language or an object. Because of this, there is no need for a fixed data model. The following types exist:
-> KV - eventually consistent
Apache Cassandra
Dynamo
Riak
-> KV - hierarchical
InterSystems Cache
-> KV - cache in RAM
memcached
-> KV - solid state or rotating disk
BidTable
Couchbase Server
MemcacheDB
-> KV - ordered
MemcacheDB
Object database:
ObjectDB
Tabular:
Apache Accumulo
BigTable
Apache Hbase
Hosted:
Datastore on Google Appengine
Amazon DynamoDB
Graph Databases:
http://en.wikipedia.org/wiki/Graph_database
http://en.wikipedia.org/wiki/Graph_theory
Graph databases are based on graph theory. Graph databases employ nodes, properties, and edges. Nodes are very similar in nature to the objects that object-oriented programmers will be familiar with
Nodes represent entities such as people, businesses, accounts, or any other item you might want to keep track of. Properties are pertinent information that relate to nodes. For instance, if "Wikipedia" were one of the nodes, one might have it tied to properties such as "website", "reference material", or "word that starts with the letter 'w'", depending on which aspects of "Wikipedia" are pertinent to the particular database. Edges are the lines that connect nodes to nodes or nodes to properties and they represent the relationship between the two. Most of the important information is really stored in the edges. Meaningful patterns emerge when one examines the connections and interconnections of nodes, properties, and edges.
Graph database projects
Neo4j -> A highly scalable open source graph database that supports ACID, has high-availability clustering for enterprise deployments, and comes with a web-based administration tool that includes full transaction support and visual node-link graph explorer. Neo4j is accessible from most programming languages using its built-in REST web API interface. Neo4j is the most popular graph database in use today.
http://en.wikipedia.org/wiki/Big_data
Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, transfer, analysis, and visualization. The trend to larger data sets is due to the additional information derivable from analysis of a single large set of related data, as compared to separate smaller sets with the same total amount of data, allowing correlations to be found to "spot business trends, determine quality of research, prevent diseases, link legal citations, combat crime, and determine real-time roadway traffic conditions
As of 2012, limits on the size of data sets that are feasible to process in a reasonable amount of time were on the order of exabytes of data. Scientists regularly encounter limitations due to large data sets in many areas, including meteorology, genomics, connectomics, complex physics simulations, and biological and environmental research. The limitations also affect Internet search, finance and business informatics. Data sets grow in size in part because they are increasingly being gathered by ubiquitous information-sensing mobile devices, aerial sensory technologies (remote sensing), software logs, cameras, microphones, radio-frequency identification readers, and wireless sensor networks. The world's technological per-capita capacity to store information has roughly doubled every 40 months since the 1980s; as of 2012, every day 2.5 quintillion (2.5×1018) bytes of data were created. The challenge for large enterprises is determining who should own big data initiatives that straddle the entire organization.
Big data is difficult to work with using most relational database management systems and desktop statistics and visualization packages, requiring instead "massively parallel software running on tens, hundreds, or even thousands of servers". What is considered "big data" varies depending on the capabilities of the organization managing the set, and on the capabilities of the applications that are traditionally used to process and analyze the data set in its domain. "For some organizations, facing hundreds of gigabytes of data for the first time may trigger a need to reconsider data management options. For others, it may take tens or hundreds of terabytes before data size becomes a significant consideration
External Link:
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
http://readwrite.com/2011/04/20/5-graph-databases-to-consider#awesm=~ojivymypzN5PBX
http://jasperpeilee.wordpress.com/2011/11/25/a-survey-on-graph-databases/
http://stackoverflow.com/questions/tagged/neo4j
http://docs.neo4j.org/chunked/milestone/introduction-pattern.html#_working_with_relationships
cypher-query-lang:
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
http://readwrite.com/2011/04/20/5-graph-databases-to-consider
Of the major categories of NoSQL databases - document-oriented databases, key-value stores and graph databases - we've given the least attention to graph databases on this blog. That's a shame, because as many have pointed out it may become the most significant category.
Graph databases apply graph theory to the storage of information about the relationships between entries. The relationships between people in social networks is the most obvious example. The relationships between items and attributes in recommendation engines is another. Yes, it has been noted by many that it's ironic that relational databases aren't good for storing relationship data. Adam Wiggins from Heroku has a lucid explanation of why that is here. Short version: among other things, relationship queries in RDBSes can be complex, slow and unpredictable. Since graph databases are designed for this sort of thing, the queries are more reliable.
Google has its own graph computing system called Pregel (you can find the paper on the subject here), but there are several commercial and open source graph databases available. Let's look at a few.
proprietary AGPL. Neo4j is ACID compliant. It's Java based but has bindings for other languages, including Ruby and Python.
Neo Technologies cites several customers, though none of them are household names.
Here's a fun illustration of how relationship data in graph databases works, from an InfoQ article by Neo Technologies COO Peter Neubauer:
There is no stable release of FlockDB, and there's some controversy as to whether it can be truly referred to as a graph database. In a DevWebPro article Michael Marr wrote:
The biggest difference between FlockDB and other graph databases like Neo4j and OrientDB is graph traversal. Twitter's model has no need for traversing the social graph. Instead, Twitter is only concerned about the direct edges (relationships) on a given node (account). For example, Twitter doesn't want to know who follows a person you follow. Instead, it is only interested in the people you follow. By trimming off graph traversal functions, FlockDB is able to allocate resources elsewhere.
This lead MyNoSQL blogger Alex Popescu to write: "Without traversals it is only a persisted graph. But not a graph database."
However, because it's in use at one of the largest sites in the world, and because it may be simpler than other graph DBs, it's worth a look.
AllegroGraph is a proprietary product of Franz Inc., which markets a number of Semantic Web products - including its flagship set of LISP-based development tools. The company claims Pfizer, Ford, Kodak, NASA and the Department of Defense among its AllegroGraph customers.
GraphDB is graph database built in .NET by the German company sones. sones was founded in 2007 and received a new round of funding earlier this year, said to be a "couple million" Euros. The community edition is available under an APL 2 license, while the enterprise edition is commercial and proprietary. It's available as a cloud-service through Amazon S3 or Microsoft Azure.
According to Gavin Clarke at The Register: "InfiniteGraph map is already being used by the CIA and Department of Defense running on top of the existing Objectivity/DB database and analysis engine."
You can find more by looking at the Wikipedia entry for graph databases or NoSQLpedia.
http://googleresearch.blogspot.in/2009/06/large-scale-graph-computing-at-google.html
http://jasperpeilee.wordpress.com/2011/11/25/a-survey-on-graph-databases/
http://en.wikipedia.org/wiki/Relational_database
A relational database is a database that has a collection of tables of data items, all of which is formally described and organized according to the relational model. The term is in contrast to only one table as the database, and in contrast to other models which also have many tables in one database.
In the relational model, each table schema must identify a column or group of columns, called the primary key, to uniquely identify each row. A relationship can then be established between each row in the table and a row in another table by creating a foreign key, a column or group of columns in one table that points to the primary key of another table. The relational model offers various levels of refinement of table organization and reorganization called database normalization. (See Normalization below.) The database management system (DBMS) of a relational database is called an RDBMS, and is the software of a relational database.
NoSQL: Not only SQL
http://en.wikipedia.org/wiki/NoSQL
http://nosql-database.org/
The name attempted to label the emergence of a growing number of non-relational, distributed data stores that often did not attempt to provide atomicity, consistency, isolation and durability guarantees that are key attributes of classic relational database systems.
A NoSQL database provides a mechanism for storage and retrieval of data that employs less constrained consistency models than traditional relational databases. Motivations for this approach include simplicity of design, horizontal scaling and finer control over availability. NoSQL databases are often highly optimized key–value stores intended for simple retrieval and appending operations, with the goal being significant performance benefits in terms of latency and throughput. NoSQL databases are finding significant and growing industry use in big data and real-time web applications. NoSQL systems are also referred to as "Not only SQL" to emphasize that they do in fact allow SQL-like query languages to be used.
There have been various approaches to classify NoSQL databases, each with different categories and subcategories. Because of the variety of approaches and overlaps it is difficult to get and maintain an overview of non-relational databases. Nevertheless, the basic classification that most would agree on is based on data model. A few of these and their prototypes are:
- Column: HBase, Accumulo
- Document: MongoDB, Couchbase, Apache CouchDB
- Key-value : Dynamo, Riak, Redis, Cache, Project Voldemort, Apache Cassandra, Memcached
- Graph: Neo4J, Allegro, Virtuoso
| Term | Matching Database |
|---|---|
| KV Store | Keyspace, Flare, SchemaFree, RAMCloud, Oracle NoSQL Database (OnDB) |
| KV Store - Eventually consistent | Dynamo, Voldemort, Dynomite, SubRecord, Mo8onDb, DovetailDB |
| KV Store - Hierarchical | GT.m, Cache |
| KV Store - Ordered | TokyoTyrant, Lightcloud, NMDB, Luxio, MemcacheDB, Actord |
| KV Cache | Memcached, Repcached, Coherence, Infinispan, EXtremeScale, JBossCache, Velocity, Terracoqua |
| Tuple Store | Gigaspaces, Coord, Apache River |
| Object Database | ZopeDB, DB40, Shoal |
| Document Store | CouchDB, Cloudant, Couchbase, MongoDB, Jackrabbit, XML-Databases, ThruDB, CloudKit, Prsevere, Riak-Basho, Scalaris |
| Wide Columnar Store | BigTable, HBase, Apache Cassandra, Hypertable, KAI, OpenNeptune, Qbase, KDI |
Document Store:
Different implementations offer different ways of organizing and/or grouping documents:
- Collections
- Tags
- Non-visible Metadata
- Directory hierarchies
Documents are addressed in the database via a unique key that represents that document. One of the other defining characteristics of a document-oriented database is that, beyond the simple key-document (or key–value) lookup that you can use to retrieve a document, the database will offer an API or query language that will allow retrieval of documents based on their contents. Some NoSQL document stores offer an alternative way to retrieve information using MapReduce techniques, in CouchDB the usage of MapReduce is mandatory if you want to retrieve documents based on the contents, this is called "Views" and it's an indexed collection with the results of the MapReduce algorithms.
NAME Language Notes
Apache CouchDB Erlang JSON database
MongoDB c++, C#, Go BSON store (binary format json)
SimpleDB Erlang Online Service
Graph:
This kind of database is designed for data whose relations are well represented as a graph (elements interconnected with an undetermined number of relations between them). The kind of data could be social relations, public transport links, road maps or network topologies, for example.
Main article: Graph database
FlockDB Scala
InfiniteGraph Java
Neo4j Java
AllegroGraph SPAROL RDF GraphStore
Key-Value Stores:
Key–value stores allow the application to store its data in a schema-less way. The data could be stored in a datatype of a programming language or an object. Because of this, there is no need for a fixed data model. The following types exist:
-> KV - eventually consistent
Apache Cassandra
Dynamo
Riak
-> KV - hierarchical
InterSystems Cache
-> KV - cache in RAM
memcached
-> KV - solid state or rotating disk
BidTable
Couchbase Server
MemcacheDB
-> KV - ordered
MemcacheDB
Object database:
ObjectDB
Tabular:
Apache Accumulo
BigTable
Apache Hbase
Hosted:
Datastore on Google Appengine
Amazon DynamoDB
Graph Databases:
http://en.wikipedia.org/wiki/Graph_database
http://en.wikipedia.org/wiki/Graph_theory
Graph databases are based on graph theory. Graph databases employ nodes, properties, and edges. Nodes are very similar in nature to the objects that object-oriented programmers will be familiar with
Nodes represent entities such as people, businesses, accounts, or any other item you might want to keep track of. Properties are pertinent information that relate to nodes. For instance, if "Wikipedia" were one of the nodes, one might have it tied to properties such as "website", "reference material", or "word that starts with the letter 'w'", depending on which aspects of "Wikipedia" are pertinent to the particular database. Edges are the lines that connect nodes to nodes or nodes to properties and they represent the relationship between the two. Most of the important information is really stored in the edges. Meaningful patterns emerge when one examines the connections and interconnections of nodes, properties, and edges.
Graph database projects
Neo4j -> A highly scalable open source graph database that supports ACID, has high-availability clustering for enterprise deployments, and comes with a web-based administration tool that includes full transaction support and visual node-link graph explorer. Neo4j is accessible from most programming languages using its built-in REST web API interface. Neo4j is the most popular graph database in use today.
http://en.wikipedia.org/wiki/Big_data
Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, transfer, analysis, and visualization. The trend to larger data sets is due to the additional information derivable from analysis of a single large set of related data, as compared to separate smaller sets with the same total amount of data, allowing correlations to be found to "spot business trends, determine quality of research, prevent diseases, link legal citations, combat crime, and determine real-time roadway traffic conditions
As of 2012, limits on the size of data sets that are feasible to process in a reasonable amount of time were on the order of exabytes of data. Scientists regularly encounter limitations due to large data sets in many areas, including meteorology, genomics, connectomics, complex physics simulations, and biological and environmental research. The limitations also affect Internet search, finance and business informatics. Data sets grow in size in part because they are increasingly being gathered by ubiquitous information-sensing mobile devices, aerial sensory technologies (remote sensing), software logs, cameras, microphones, radio-frequency identification readers, and wireless sensor networks. The world's technological per-capita capacity to store information has roughly doubled every 40 months since the 1980s; as of 2012, every day 2.5 quintillion (2.5×1018) bytes of data were created. The challenge for large enterprises is determining who should own big data initiatives that straddle the entire organization.
Big data is difficult to work with using most relational database management systems and desktop statistics and visualization packages, requiring instead "massively parallel software running on tens, hundreds, or even thousands of servers". What is considered "big data" varies depending on the capabilities of the organization managing the set, and on the capabilities of the applications that are traditionally used to process and analyze the data set in its domain. "For some organizations, facing hundreds of gigabytes of data for the first time may trigger a need to reconsider data management options. For others, it may take tens or hundreds of terabytes before data size becomes a significant consideration
External Link:
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
http://readwrite.com/2011/04/20/5-graph-databases-to-consider#awesm=~ojivymypzN5PBX
http://jasperpeilee.wordpress.com/2011/11/25/a-survey-on-graph-databases/
http://stackoverflow.com/questions/tagged/neo4j
http://docs.neo4j.org/chunked/milestone/introduction-pattern.html#_working_with_relationships
cypher-query-lang:
http://docs.neo4j.org/chunked/stable/cypher-query-lang.html
http://readwrite.com/2011/04/20/5-graph-databases-to-consider
Of the major categories of NoSQL databases - document-oriented databases, key-value stores and graph databases - we've given the least attention to graph databases on this blog. That's a shame, because as many have pointed out it may become the most significant category.
Graph databases apply graph theory to the storage of information about the relationships between entries. The relationships between people in social networks is the most obvious example. The relationships between items and attributes in recommendation engines is another. Yes, it has been noted by many that it's ironic that relational databases aren't good for storing relationship data. Adam Wiggins from Heroku has a lucid explanation of why that is here. Short version: among other things, relationship queries in RDBSes can be complex, slow and unpredictable. Since graph databases are designed for this sort of thing, the queries are more reliable.
Google has its own graph computing system called Pregel (you can find the paper on the subject here), but there are several commercial and open source graph databases available. Let's look at a few.
Neo4j
This is one of the most popular databases in the category, and one of the only open source options. It's the product of the company Neo Technologies, which recently moved the community edition of Neo4j from the AGPL license to the GPL license (see our coverage here). However, its enterprise edition is stillNeo Technologies cites several customers, though none of them are household names.
Here's a fun illustration of how relationship data in graph databases works, from an InfoQ article by Neo Technologies COO Peter Neubauer:
FlockDB
FlockDB was created by Twitter for relationship related analytics. Twitter's Kevin Weil talked about the creation of the database, along with Twitter's use of other NoSQL databses, at Strange Loop last year. You can find our coverage here.There is no stable release of FlockDB, and there's some controversy as to whether it can be truly referred to as a graph database. In a DevWebPro article Michael Marr wrote:
The biggest difference between FlockDB and other graph databases like Neo4j and OrientDB is graph traversal. Twitter's model has no need for traversing the social graph. Instead, Twitter is only concerned about the direct edges (relationships) on a given node (account). For example, Twitter doesn't want to know who follows a person you follow. Instead, it is only interested in the people you follow. By trimming off graph traversal functions, FlockDB is able to allocate resources elsewhere.
This lead MyNoSQL blogger Alex Popescu to write: "Without traversals it is only a persisted graph. But not a graph database."
However, because it's in use at one of the largest sites in the world, and because it may be simpler than other graph DBs, it's worth a look.
AllegroGraph
AllegroGraph is a graph database built around the W3C spec for the Resource Description Framework. It's designed for handling Linked Data and the Semantic Web, subjects we've written about often. It supports SPARQL, RDFS++, and Prolog.AllegroGraph is a proprietary product of Franz Inc., which markets a number of Semantic Web products - including its flagship set of LISP-based development tools. The company claims Pfizer, Ford, Kodak, NASA and the Department of Defense among its AllegroGraph customers.
GraphDB
GraphDB is graph database built in .NET by the German company sones. sones was founded in 2007 and received a new round of funding earlier this year, said to be a "couple million" Euros. The community edition is available under an APL 2 license, while the enterprise edition is commercial and proprietary. It's available as a cloud-service through Amazon S3 or Microsoft Azure.
InfiniteGraph
InfiniteGraph is a proprietary graph database from Objectivity, the company behind the object database of the same name. Its goal is to create a graph database with "virtually unlimited scalability."According to Gavin Clarke at The Register: "InfiniteGraph map is already being used by the CIA and Department of Defense running on top of the existing Objectivity/DB database and analysis engine."
Others
There are many more graph databases, including OrientDB, InfoGrid and HypergraphDB. Ravel is working on an open source implementation of Pregel. Microsoft is getting into the game with the Microsoft Reasearch project Trinity.You can find more by looking at the Wikipedia entry for graph databases or NoSQLpedia.
http://googleresearch.blogspot.in/2009/06/large-scale-graph-computing-at-google.html
http://jasperpeilee.wordpress.com/2011/11/25/a-survey-on-graph-databases/
Subscribe to:
Posts (Atom)